减少 60% 耗时,百度智能云大规模落地 Intel 至强 6 QAT 硬件加速虚拟机热迁移
作者:xxinjiang2026.06.01 10:51浏览量:210简介:如何在保证迁移成功率的同时,缩短迁移时间、降低资源开销、减少用户感知,已成为热迁移技术演进的关键问题
1. 背景:热迁移的挑战与痛点
虚机热迁移是云平台和虚拟化基础设施中的核心能力之一,广泛应用于宿主机维护、负载均衡、故障规避等场景。其目标是在尽量不影响业务运行的前提下,将虚拟机从源宿主机迁移到目标宿主机。
随着云上业务规模与负载复杂度不断提升,热迁移在大规模集群中的挑战日益凸显。一方面,迁移过程中需要反复拷贝内存页,当虚拟机内存较大或脏页写入频率较高时,迁移时间显著延长,甚至可能出现迁移失败或回滚;另一方面,迁移本身会带来额外的 CPU、内存带宽和网络带宽开销,容易与同宿主机或同网络域内的在线业务争抢资源,影响整体集群稳定性。
更关键的是,在迁移收敛阶段,虚拟机仍不可避免地经历短暂停顿(downtime)。当迁移耗时过长或资源竞争严重时,这种停顿会被用户明显感知,表现为请求延迟抖动、吞吐下降甚至业务超时,对时延敏感或高 SLA 要求的场景尤为不友好。因此,如何在保证迁移成功率的同时,缩短迁移时间、降低资源开销、减少用户感知,已成为热迁移技术演进的关键问题。
2. 方案创新:引入 CPU 内置的 QAT 硬件加速
在热迁移过程中,内存压缩是降低网络带宽占用、缩短迁移时间的关键手段。然而,传统方案中压缩与解压完全依赖 CPU 执行,高强度计算会显著消耗宿主机资源,进而影响同机虚拟机的业务性能。
为解决这一矛盾,百度智能云联合英特尔,基于最新的英特尔®至强® 6 性能核处理器 Granite Rapids(GNR)平台,探索并落地了基于英特尔® 数据保护与压缩加速技术(Intel®QuickAssist Technology,英特尔®QAT)的虚拟机热迁移硬件加速方案。
英特尔®至强® 6 处理器内置的 QAT 硬件加速引擎,在热迁移场景中提供了以下关键能力:
CPU 负载卸载:压缩/解压计算从 CPU 核心转移至专用硬件,释放通用算力资源。
高并行处理:支持多流并行压缩/解压,处理速度显著高于 CPU 软件实现。
主流算法兼容:支持 lz4、zlib 等主流压缩算法,可无缝对接现有软件栈。
全流程覆盖:同时支持压缩与解压,覆盖迁移发送端与接收端的完整链路。
基于这些能力,我们将计算密集的内存压缩工作从 CPU 软件栈卸载至 CPU 内置的 QAT 硬件加速引擎,在保障迁移一致性与稳定性的同时,有效缩短了迁移时间、降低了 CPU 峰值占用,并显著减轻了对用户业务性能的影响。
目前,该方案已在百度智能云完成大规模生产环境验证与推广,成为支撑高并发、低感知虚拟机热迁移的重要基础能力。
3. 方案对比:引入 QAT 前后有何不同?
3.1. 引入 QAT 前的方案
在引入 QAT 加速之前,虚拟机热迁移中的内存页数据处理完全依赖宿主机 CPU 软件栈完成。迁移过程中,虚拟机内存页在发送前需要压缩,以减少网络传输数据量,压缩与解压计算均由 CPU 核心执行。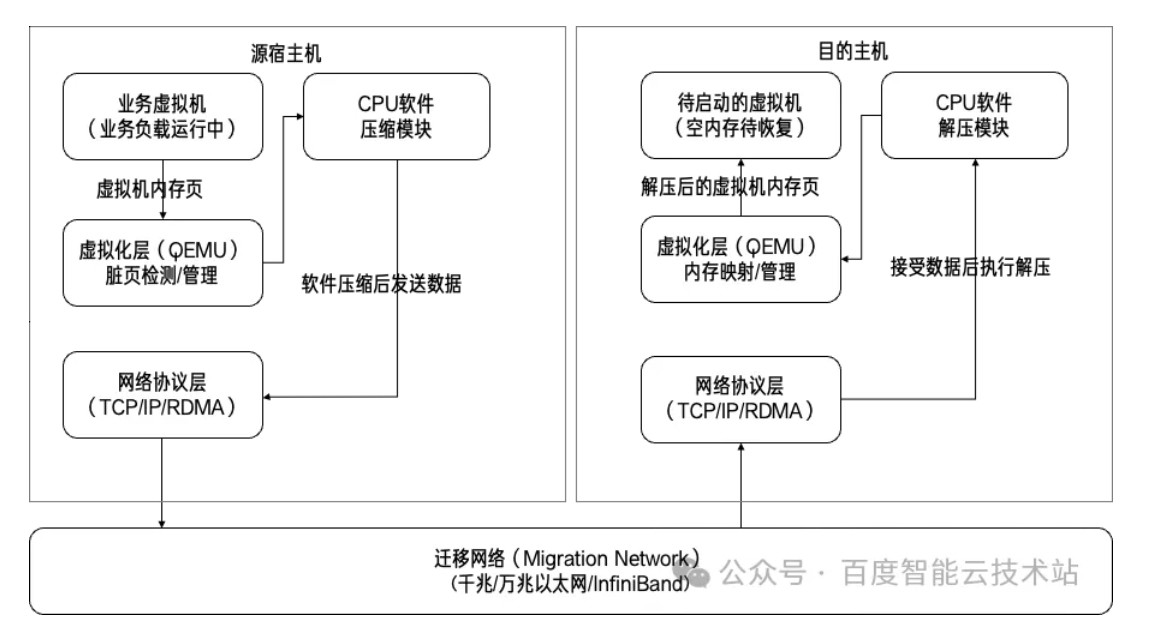
具体流程如下:
预拷贝阶段:源宿主机 CPU 同时承担「脏页检测」和「软件压缩」两项工作。它先扫描运行中虚拟机的内存页,识别被业务修改的脏页,再通过 CPU 内核态的压缩算法(如 lz4 / zlib)进行软件压缩。
数据传输阶段:压缩后的脏页通过迁移网络发送至目标宿主机,传输效率受限于压缩后的数据量和网络带宽。
解压缩与恢复阶段:目标宿主机 CPU 接收压缩包后执行软件解压缩,将原始内存页写入待启动虚拟机的空内存中。经过多轮迭代后,CPU 暂停源虚拟机,拷贝最后一批脏页并完成解压缩与内存同步。
该方案的核心瓶颈在于 CPU 资源冲突:压缩/解压的计算开销会抢占业务虚拟机的 CPU 算力,导致业务性能下降;同时,大内存虚拟机(如 128GB 以上)的软件压缩耗时较长,会延长迁移时间和业务中断窗口。
3.2. 引入 QAT 后的方案
英特尔®至强® 6 Granite Rapids(GNR)性能核处理器拥有更多内核、更高内存带宽和更多 CXL 2.0 通道,支持 PCIe 5.0。其性能核具备更强的处理能力,是 AI、HPC 和存储等工作负载的理想选择。
处理器内置的 QAT 硬件加速引擎,支持压缩/解压缩、加密/解密、数据完整性校验,能有效卸载 CPU 核心的负载。在热迁移场景中,我们使用 QAT 对内存页数据进行压缩与解压卸载。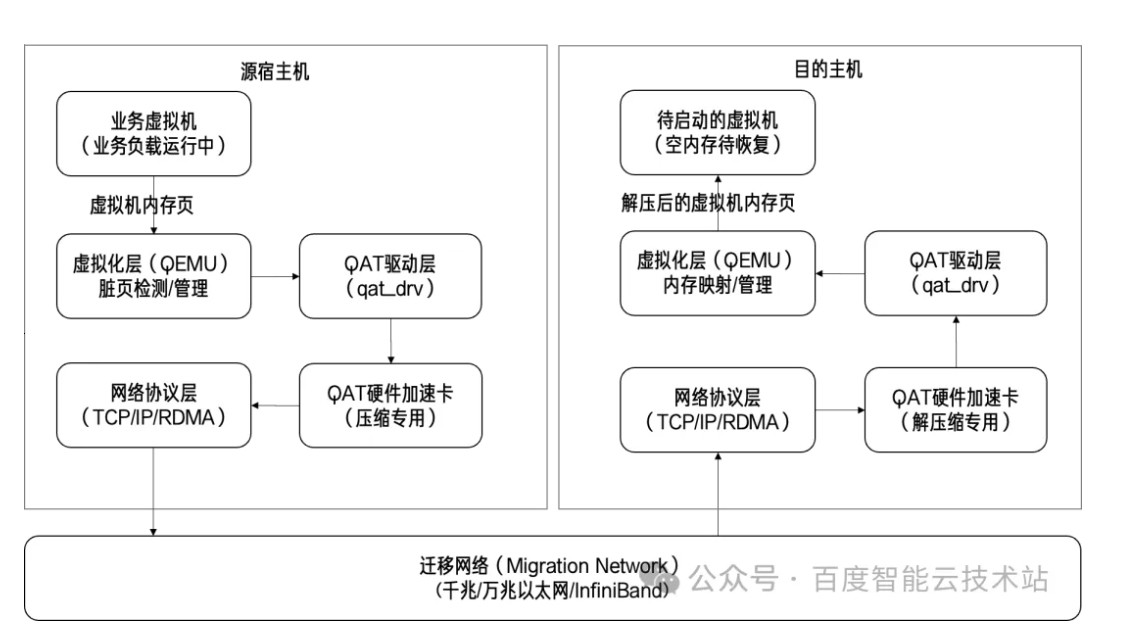
具体流程如下:
预拷贝阶段:源宿主机 CPU 仅负责「脏页检测」和虚拟化层管理,识别出的脏页数据通过 QAT 用户态压缩库(qatzip)提交至 CPU 内置的 QAT 硬件执行并行压缩(支持 lz4 / zlib 等主流算法),无需占用 CPU 核心进行计算。
数据传输阶段:QAT 压缩后的脏页数据量更小,网络传输效率显著提升。压缩包通过 TCP/IP 或 RDMA 协议传输至目标宿主机。
解压缩与恢复阶段:目标宿主机的 QAT 硬件接收压缩包后,执行硬件级并行解压缩,解压后的原始内存页直接写入待启动虚拟机的内存。最后一批脏页的压缩/解压同样由 QAT 完成,CPU 核心仅负责虚拟机的暂停与启动控制。
4. 落地实践:从 Demo 到生产环境的联合攻关
在方案推进过程中,我们与英特尔工程师团队开展了深度联合攻关,重点围绕虚拟机热迁移在云上大规模落地面临的关键挑战进行优化,包括:
高并发迁移场景下的稳定性问题,确保多虚拟机同时迁移时系统资源不发生争抢或异常抖动;
部分虚拟机迁移效率偏低的问题,针对内存占用大、写入速率不均衡等典型场景进行针对性优化;
硬件加速与云平台调度体系的协同,确保 QAT 加速能力无缝融入现有迁移流程。
最终,我们完成了从实验 Demo 到生产环境的完整落地,使基于 QAT 的虚拟机热迁移方案在云环境中满足迁移稳定性、高并发与可运维性等核心要求,为规模化部署奠定了坚实基础。
5. 百度智能云落地收益
基于上述 QAT 硬件能力,百度智能云在云服务器 BCC 中进行了落地与规模化验证,取得了以下收益:
迁移性能显著提升
在 64GB 虚拟机迁移场景中,迁移总时长由 33 秒降低至 12 秒,整体缩短约 60%。 对于内存占用高、写吞吐较低的虚拟机类型,性能收益尤为明显。同时,由于压缩效率提升,迁移过程中的网络带宽占用明显下降,链路更加稳定,有效降低了对集群网络的冲击。
此外,集群运维效率也得到提升,节点维护窗口明显缩短,为后续自动化调度和弹性伸缩提供了基础能力。
CPU 资源大幅节省
通过将内存压缩计算从 CPU 核心卸载至 CPU 内置的 QAT 硬件,迁移期间 宿主机 CPU 使用率下降 20% 以上,显著减少了对业务虚拟机的性能影响,提升了整体用户体验。
业务中断窗口缩小
得益于 QAT 的高效压缩,预拷贝阶段的脏页收敛速度更快,最终虚拟机暂停的中断窗口降至「十毫秒级」,满足金融、电商等业务的高可用要求。
高负载场景覆盖
该方案对「大内存虚拟机」场景(如分布式缓存、CDN、离线业务)的加速效果尤为明显,可在业务不中断的前提下完成快速迁移。
6. 结语:持续深化合作,夯实智能时代底座
百度智能云与英特尔持续深化战略合作,围绕 CPU 选型与定制化、软硬件协同优化以及 AI 训练与推理性能提升等核心领域展开深入创新协作。
双方充分发挥各自在云计算与芯片技术领域的优势,从底层硬件架构与关键特性出发,推进系统级与应用级的联合优化,全面释放算力潜能,持续提升 AI 与云服务的整体性能与效率,为百度智能云构建稳定、高效、可持续演进的算力基础设施,夯实智能时代的技术底座。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册