深入解读 GPUDirect PCIe P2P 驱动代码:Mailbox 和 BAR1 的实现原理及对比
作者:xxinjiang2026.06.08 16:52浏览量:285简介:深入解读 GPUDirect PCIe P2P 驱动代码:Mailbox 和 BAR1 的实现原理及
1. 引言
自 2022 年起,NVIDIA 开源了其 Linux GPU 内核模块代码。得益于此,我们有机会一窥 GPU 内部的运行逻辑。近期,开源组织 tinygrad 发布了一项支持部分高性能显卡 GPUDirect PCIe P2P 功能的工作。值得注意的是,在 NVIDIA 的官方驱动中并未支持这些显卡的 GPUDirect PCIe P2P 功能,但从硬件设计而言,它们完全具备该能力。
我们以此为契机,从本次驱动限制与解锁的角度,深入了解 GPUDirect PCIe P2P 的实现细节。本文包含以下内容:
本次解锁 GPUDirect PCIe P2P 功能的思路;
GPUDirect PCIe P2P 的不同种类及其对比;
结合驱动代码解析 GPUDirect PCIe P2P 的实现逻辑。
2. GPUDirect P2P 背景
在 GPUDirect P2P 技术出现之前,多 GPU 系统的通信模式普遍依赖 「CPU 中转」,即数据回弹(Bounce Buffer)机制:当 GPU A 需要向 GPU B 传输数据时,需先将数据从 GPU A 的显存拷贝到系统内存(Host Memory),再由 CPU 调度,将数据从系统内存拷贝到 GPU B 的显存。这一过程不仅带宽瓶颈显著、延迟高,还会大量浪费 CPU 资源。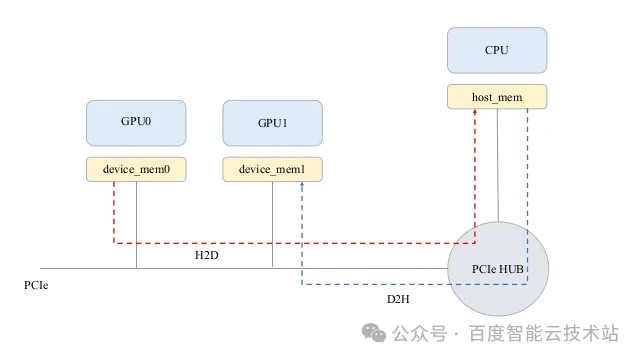
GPUDirect P2P 技术主要用于单机 GPU 间的高速通信。简而言之,它使得 GPU 之间可以通过总线直接访问目标 GPU 的显存,从而避免了通过 CPU Host Memory 作为中转的消耗,大大降低了数据交换的延迟。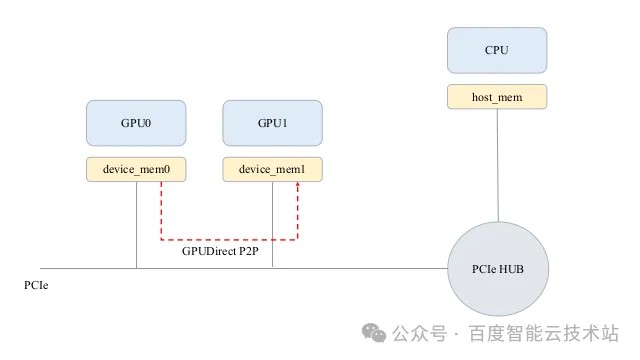
3. P2P Support Patch:解锁思路
本次开源社区针对部分 GPU 的 P2P 能力做出了解锁,主要可以参考以下两个项目:
3.1. 原厂驱动限制 GPUDirect P2P 的方式
被限制 P2P 能力的 GPU 主要为 PCIe 版 GPU(即不支持 NVLink)。PCIe 支持 GPUDirect P2P 有 Mailbox 与 BAR1 两种路径,驱动会针对这两种路径分别施加限制。有关 P2P 不同类型的相关内容可以参考本文第 4 部分。
原厂驱动主要通过以下 4 个核心卡点对 GPU 的 P2P 能力做限制:
1.ReBAR 启用的限制
BAR1 P2P 的核心前提是 「全显存静态映射到 BAR1」,而小 BAR1 空间无法满足要求。驱动通过 NVreg_EnableResizableBar 内核模块参数,默认跳过 ReBAR 配置。即使 BIOS 开启该功能,驱动也不会把 BAR1 空间放大到显存空间大小。
2.HAL 函数架构锁
BAR1 P2P 的核心实现函数(如映射创建 / 删除、能力检测等)仅会绑定给专业级架构。而对于一些 Blackwell 架构 GPU 的 HAL 实现,驱动会直接返回不支持。
3. GMMU 孔径限制
一部分高性能 GPU 的 GMMU 硬件上限制了 GMMU_APERTURE_PEER 的 aperture 类型。原厂驱动在构建 P2P 页表时会触发 MMU 错误(例如 cudaErrorMapBufferObjectFailed)。
4.SKU 锁
驱动默认 P2P 类型为 Mailbox P2P,而一些高性能 GPU 的 Mailbox 硬件被锁定。驱动会通过 SKU 标记,直接判定一部分 GPU 不支持 P2P;同时,原厂驱动又不会给这些 GPU 走 BAR1 P2P 的流程,因此直接返回不支持。
3.2. Patch 核心改动
开源社区的一组 Patch 以 BAR1 方式支持 GPU P2P,核心 Commit 如下:
https://github.com/NVIDIA/open-gpu-kernel-modules/commit/9e39420
https://github.com/NVIDIA/open-gpu-kernel-modules/commit/176269d
https://github.com/tinygrad/open-gpu-kernel-modules/issues/29#issuecomment-2765260985
下面结合代码看一下支持 P2P 的主要思路。
3.2.1. 强制开启 ReBAR 能力检测
if (NVreg_EnableResizableBar == 0)
{
nv_printf(NV_DBG_INFO, "NVRM: resizable BAR disabled by regkey, skipping\n");
return 0;
}
Patch 将这段判断去掉,继续执行后续的 ReBAR 检测与配置:
在原厂驱动中,只要用户没有手动通过内核参数开启 NVreg_EnableResizableBar=1,驱动会直接跳过 ReBAR 的配置流程。即使 GPU 和 BIOS 已经开启了 ReBAR,也只会保留默认的 256MB 小 BAR1 空间。注释掉这段代码后,驱动则会检测 GPU 的 ReBAR 能力,将 BAR1 空间重配置为等于显存总大小,为 BAR1 P2P 提供最核心的硬件前提 —— 全量显存静态线性映射到 BAR1 空间。
3.2.2. 绑定 Hopper 的 BAR1 P2P HAL 实现
将 KernelBus 的几个 BAR1 P2P HAL 函数指针,从默认的通用实现(直接返回 NOT_SUPPORTED / FALSE)替换为 Hopper(GH100)架构实现。
BAR1 P2P 更多依赖于 PCIe 本身的能力。Hopper 架构原生支持了 BAR1 P2P,推测 Blackwell 架构在硬件上和 Hopper 的 BAR1 P2P 逻辑完全兼容,所以可以沿用 Hopper 的检测、映射创建 / 删除、DMA 信息获取等核心操作。
替换的 HAL 实现如下:
3.2.3. GPU 的 GMMU 页表构建问题
这里的改动解决了一部分高性能 GPU 不支持 PEER 孔径的问题,分两个部分来看:
改动 1:替换 P2P 的 GMMU Aperture 类型
// 原代码
gmmuFieldSetAperture(&pPteFmt->fldAperture, aperture, pte.v8);
// 改动后
if (aperture == GMMU_APERTURE_PEER) {
gmmuFieldSetAperture(&pPteFmt->fldAperture, GMMU_APERTURE_SYS_NONCOH, pte.v8);
} else {
gmmuFieldSetAperture(&pPteFmt->fldAperture, aperture, pte.v8);
}
专业级 GPU 的 GMMU 支持 GMMU_APERTURE_PEER,这个 Aperture 的作用是告诉 GMMU:这个虚拟地址对应的是对端 GPU 的显存,需要直接发起 PCIe P2P 事务,而不是访问本地显存或系统内存。然而,一部分高性能 GPU 的 GMMU 硬件上限制了这个 Aperture。即使驱动设置了该孔径,GMMU 也会触发 MMU 页错误,导致 P2P 映射直接失败。这是原厂驱动在一些 GPU 上无法启用 P2P 的核心原因之一。
这里把 PEER 孔径替换为所有 GPU 都支持的 GMMU_APERTURE_SYS_NONCOH。这个孔径原本用于 GPU 访问系统内存,而对端 GPU 的 BAR1 空间在 PCIe 总线域中,本身就是一个标准的 64 位系统物理地址。使用这个孔径完全可以正常访问,从而绕过对 PEER 孔径的限制。
改动 2:新增 BAR1 总线地址参数,修复物理地址翻译
// 原函数参数
nvGpuOpsBuildExternalAllocPtes(..., gpuExternalMappingInfo *pGpuExternalMappingInfo)
// 改动后新增参数
nvGpuOpsBuildExternalAllocPtes(..., gpuExternalMappingInfo *pGpuExternalMappingInfo, RmPhysAddr bar1BusAddr)
// 新增地址赋值逻辑
if (aperture == GMMU_APERTURE_PEER) {
fabricBaseAddress = bar1BusAddr;
}
fabricBaseAddress 是 GMMU 页表中用于设置 PCIe 总线基地址的关键字段。在原厂驱动中,这个字段原本用于 NVLink 的 Fabric 地址。在 BAR1 P2P 场景下,需要将其设置成对端 GPU 的 BAR1 总线基地址。
这里给页表构建函数新增了 bar1BusAddr 参数。在构建 P2P 页表时,直接把对端 GPU 的 BAR1 总线基地址赋值给 fabricBaseAddress。当我们用 SYS_NONCOH 孔径访问时,GMMU 会自动把虚拟地址翻译成 fabricBaseAddress + 页内偏移,也就是对端 GPU 的 BAR1 总线物理地址。这正好完成了 P2P 访问的地址翻译,让 GPU 能正确找到对端显存的 PCIe 地址。
3.2.4. P2P Map 的入口分支
在 kbusCreateP2PMapping_GP100 和 kbusRemoveP2PMapping_GP100 两个 P2P 映射的入口函数中,新增了 BAR1 P2P 类型的分支判断:
// 新增的删除映射分支
if (FLD_TEST_DRF(_P2PAPI, _ATTRIBUTES, _CONNECTION_TYPE, _PCIE_BAR1, attributes))
{
return kbusRemoveP2PMappingForBar1P2P_HAL(pGpu0, pKernelBus0, pGpu1, pKernelBus1, attributes);
}
原厂驱动的 P2P 映射入口函数,原本只支持两种连接类型:_PCIE(对应 Mailbox P2P)和 _NVLINK(对应 NVLink P2P),没有 _PCIE_BAR1 的分支。所以即使我们前面强制指定了 BAR1 P2P 类型,驱动在调用映射函数时,也会因为找不到对应的分支,直接返回不支持,出现 mapping of buffer object failed 的报错。
这里给 P2P 映射入口新增了 BAR1 类型的分支。当驱动收到 BAR1 P2P 的请求时,会正确调用之前绑定的 Hopper HAL 函数,完成 P2P 地址映射的创建与删除。
3.2.5. 绕过 SKU 锁,默认启用 BAR1 P2P
改动 1:P2P 权限覆盖
// 原代码:pKernelBif->p2pOverride = BIF_P2P_NOT_OVERRIDEN;
// 改动后:
pKernelBif->p2pOverride = 0x11;
p2pOverride 是驱动内部的 P2P 权限强制覆盖开关。推测 0x11 是驱动内部定义的启用值,可以忽略 GPU 的 SKU 类型限制。
原厂驱动会根据 GPU 的 SKU(消费级 / 专业级)标记,直接判定一部分 GPU 不支持 P2P。这个改动直接绕过了 SKU 锁。
改动 2:强制指定 P2P 类型为 BAR1 P2P
原代码:pKernelBif->forceP2PType = NV_REG_STR_RM_FORCE_P2P_TYPE_DEFAULT;
// 改动后:
pKernelBif->forceP2PType = NV_REG_STR_RM_FORCE_P2P_TYPE_BAR1P2P;
原厂驱动默认 P2P 类型为 DEFAULT,这会优先使用 Mailbox P2P。但一些高性能 GPU 的 Mailbox 硬件会被锁定,即使开启了权限,也会因为 Mailbox 不可用而返回 P2P 不支持。所以这里选择使用 BAR1 P2P 类型。
4. GPUDirect PCIe P2P 的分类与实现
从上面可以看到,本次解锁 P2P 主要针对的是基于 PCIe 实现的 GPUDirect P2P,不涉及基于 NVLink 实现的 P2P。
在 NVIDIA 开源驱动中可以看到,P2P 有如下几种不同的类型:
typedef enum
{
P2P_CONNECTIVITY_UNKNOWN = 0,
P2P_CONNECTIVITY_PCIE_PROPRIETARY,
P2P_CONNECTIVITY_PCIE_BAR1,
P2P_CONNECTIVITY_NVLINK,
P2P_CONNECTIVITY_NVLINK_INDIRECT,
P2P_CONNECTIVITY_C2C,
} P2P_CONNECTIVITY;
NVIDIA 开源驱动中会对当前环境支持的 P2P 类型分别作出检测(参考 p2p_caps.c::p2pGetCapsStatus),且检测有先后顺序区别:
- C2C (Chip-to-Chip):GPU 芯片间互连,NVIDIA 的一种高速互连技术,用于连接 GPU 和其他芯片(如 Grace CPU);
- NVLink 直连:GPU 之间通过 NVLink 直接连接;
- NVLink Indirect:通过 NVSwitch 间接连接;
- PCIe P2P:
- PCIe PROPRIETARY P2P(Mailbox P2P);
- PCIe BAR1 P2P。
NVLink 与 C2C 作为 NVIDIA 自研的专用互联协议,其设计初衷便是为了实现 GPU 间的无缝内存共享,因此实现路径相对统一且直观。相比之下,基于标准 PCIe 总线的 GPUDirect P2P 则面临着更多的底层约束,演化出了 Mailbox P2P 与 BAR1 P2P 两种截然不同的实现方案。
4.1. 为什么基于 PCIe 的 GPUDirect P2P 会更复杂?
在深入解析这两种方案的具体实现之前,我们需要先理解 PCIe P2P 面临的核心挑战。简而言之,NVLink 的设计哲学是「连为一体」,从硬件层面抹平了设备界限;而 PCIe P2P 则更像是在主从架构下「为绕过 CPU 中转而打的补丁」,这种先天性的架构差异导致了其实现过程的复杂性。
1.架构哲学不同
NVLink (互联):架构设计就是扁平化的。GPU A 和 GPU B 通过 NVLink 连接后,它们之间的内存空间在硬件层面就被映射在一起了。
PCIe (主从):PCIe 的设计哲学是「以 CPU 为中心」的总线协议。它的原生逻辑是:所有设备都是外设,CPU 是主设备。数据流动默认是 设备 <-> CPU 内存,GPU 之间并没有直接的总线连接。
2.拓扑结构限制
这是 PCIe P2P 最让人头疼的地方,也是它不如 NVLink 直观的核心原因:PCIe P2P 非常依赖物理位置,需要区分是否在同 Switch 下、同 Root Port 下、同 NUMA 节点下等等。相比之下,NVLink 拓扑简单粗暴:只要连了 NVLink,就是直连,无视 PCIe 的物理位置。
而得益于 NVSwtch 连接节点内多个 GPU ,将直连模式扩展为交换网络,使任意 GPU 对之间都有等价的直连路径,构建起一个无阻塞的全互联拓扑,多级 NVLink/NVSwitch 从根本上摆脱了 PCIe 树状结构带来的层级限制和跨 RC 的复杂路由问题。
3.地址映射与一致性
NVLink:支持完美的内存一致性。GPU A 可以直接读写 GPU B 的显存,甚至支持原子操作。在程序员眼里,这几乎就是一个全局显存池。
PCIe P2P:运行时数据传输依赖 DMA 机制。GPU A 要访问 GPU B,必须先通过 OS 获取 GPU B 显存的物理地址(IOVA),然后映射到自己的 PCIe BAR 空间。这个过程涉及 IOMMU、ATS 等复杂的系统层配置。一旦 OS 或 BIOS 禁用了某些特性,P2P 就会静默失败,回退到通过 CPU 内存拷贝。这对开发者来说行为不可预期,调试成本高。
正是由于上述复杂性,NVIDIA 在 PCIe 链路上进化出了两种不同的实现方案:BAR1 P2P 和 Mailbox P2P。接下来我们将详细解析这两种方案。
4.2. PCIe P2P 支持情况
4.2.1. 如何判断
首先的问题是如何判断当前 GPU 设备是否支持 GPUDirect P2P。由于 P2P 连通性受到多方面的影响,最可靠的标准即为 NVIDIA 提供的 API cudaDeviceCanAccessPeer。返回 true 则两 GPU 节点支持 P2P,否则不支持。
注意:cudaDeviceEnablePeerAccess 是一个昂贵的操作(可能涉及 TLB 刷新和页表修改),通常只需在应用程序启动时执行一次。
__host__cudaError_t cudaDeviceCanAccessPeer ( int* canAccessPeer, int device, int peerDevice )
Queries if a device may directly access a peer device's memory.
Parameters
canAccessPeer
- Returned access capability
device
- Device from which allocations on peerDevice are to be directly accessed.
peerDevice
- Device on which the allocations to be directly accessed by device reside.
Returns
cudaSuccess, cudaErrorInvalidDevice
Description
Returns in *canAccessPeer a value of 1 if device device is capable of directly accessing memory from peerDevice and 0 otherwise. If direct access of peerDevice from device is possible, then access may be enabled by calling cudaDeviceEnablePeerAccess()
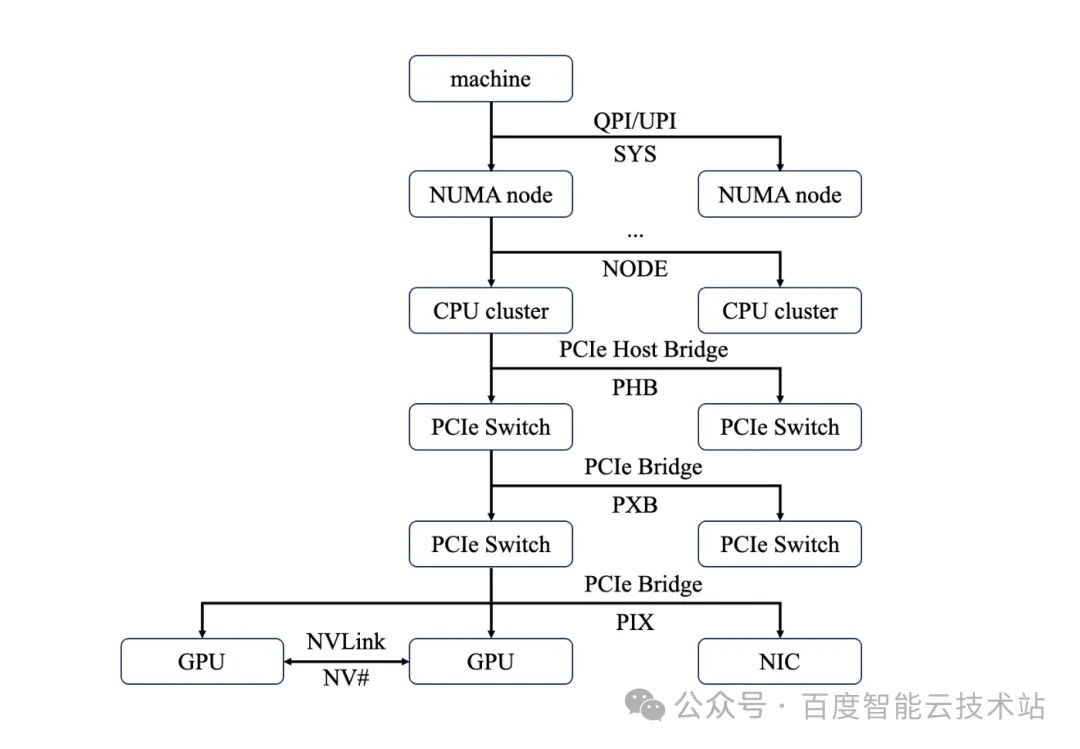
4.2.2. 拓扑结构的影响
物理拓扑结构会直接对 GPUDirect PCIe P2P 的连通性与性能造成影响。通过执行 nvidia-smi topo -m 可以直观了解到当前节点 GPU / NIC 的拓扑结构。
根据 GPU 在 PCIe 总线树上的位置,可以将物理拓扑分为三个层级。
层级一:同一 PCIe Switch 下游
这是 PCIe 方案下性能最优的拓扑结构,对应于 nvidia-smi topo -m 输出中的 PIX。
物理连接:两张 GPU 连接在同一个 PCIe Switch 芯片的不同下游端口上,该 Switch 上行连接到 CPU 的 Root Complex;
联通性:最佳状态。PCIe Switch 具备路由 P2P TLP(Transaction Layer Packet)的能力,GPU 可以直接看到对方的 BAR 空间。
通信性能:
带宽:接近线速。数据包仅在 Switch 内部转发,不经过 CPU;
延迟:最低。路径短,仅涉及 Switch 内部交换逻辑;
一致性:Switch 通常能较好地处理 Cache Coherency,减少 CPU 干预。
层级二:同一 CPU Socket,不同 PCIe Switch/Root Port
PCIe 下的次优路径,对应于 nvidia-smi topo -m 输出中的 PHB。
物理连接:GPU A 连接在 Switch 1(或 CPU Root Port A),GPU B 连接在 Switch 2(或 CPU Root Port B),但两者都挂在同一个 CPU Socket 下。
联通性:通常支持,但受固件配置影响。
数据路径为:GPU A -> Switch A -> CPU Root Complex -> Switch B -> GPU B;
数据必须经过 CPU 内部的 PCIe Host Bridge。
一个关键阻碍 - ACS (Access Control Services):
为了安全性和虚拟化隔离,现代服务器 BIOS 通常默认开启 ACS。ACS 策略会强制要求 P2P 流量必须先上行发送到 Root Complex 进行验证,甚至可能禁止 P2P 事务转发;
如果 ACS 开启并配置了强制转发到 RC,会导致性能退化。
性能:
带宽:依然较高,但受限于 CPU 内部的互连总线带宽。如果多个 GPU 对同时进行 P2P,会争抢 CPU 内部的 PCIe 路由带宽;
延迟:比同 Switch 场景高,因为增加了穿过 CPU Root Complex 的跳数。
层级三:跨 CPU Socket (Multi-Socket Topology)
这是 PCIe 方案下性能最差或最复杂的拓扑,对应于 nvidia-smi topo -m 输出中的 SYS。
物理连接:GPU A 挂在 CPU Socket 0 上,GPU B 挂在 CPU Socket 1 上。
联通性:较差,甚至不支持直接 P2P。
数据路径为:GPU A -> CPU 0 -> QPI/UPI (Intel) 或 Infinity Fabric (AMD) -> CPU 1 -> GPU B。
通信性能
带宽瓶颈:可能成为较严重的性能瓶颈。跨 Socket 通信依赖处理器间的互连链路(QPI / UPI /xGMI)。GPU 间的数据通路会与 CPU 间的内存一致性流量竞争,而 UPI 带宽通常会低于 PCIe Gen4/Gen5 的带宽;
延迟:显著增加。这个过程中使用的基于目录的缓存一致性协议,会比传统的基于总线监听的 MESI 协议逻辑更复杂,会加剧跨片互连延迟;
实际结果:在大多数 PCIe P2P 实现中(如 CUDA),驱动检测到跨 Socket 拓扑时,往往会限制直接 P2P,强制使用 系统内存中转 模式。即:GPU A -> CPU0 Mem -> CPU1 Mem -> GPU B(或者如果内存互联足够快,直接 DMA 到远端内存)。这实际上已经失去了 P2P Zero Copy 的优势。
4.3. BAR1 Mapping
BAR1 Mapping P2P 是基于标准 PCIe BAR 地址映射机制实现的 P2P 方案,利用 PCIe 规范与 ReBAR 技术实现。
4.3.1. 前置基础:PCIe BAR 与 ReBAR
PCIe 设备在系统枚举时,会通过 BAR(Base Address Register,基地址寄存器)向主机 BIOS/OS 报告自己需要的内存映射 IO(MMIO)空间。OS 会为其分配唯一的 PCIe 总线物理地址,CPU 或其他 PCIe 设备可通过该地址直接访问设备的内部资源。
对于 NVIDIA GPU,有两个核心 BAR 空间:
BAR0:固定小容量(通常 16MB),用于映射 GPU 的控制寄存器、固件接口,是 CPU 控制 GPU 的核心通道;
BAR1:原本为小容量显存访问窗口(通常 256MB)。开启 Resizable BAR(ReBAR)后,可扩容至与 GPU 显存总容量完全一致,让 CPU 可以直接寻址 GPU 的全部显存,无需窗口切换。
BAR1 P2P 的核心,就是利用 ReBAR 扩容后的 BAR1 空间,让其他 GPU 通过 PCIe 总线地址,直接访问对端 GPU 的显存。
4.3.2. 核心思想
NVIDIA 的原厂驱动中仍然复用了 GMMU 的 PEER Aperture 机制,只是底层的 fabric base address 指向的是对端 GPU 的 BAR1 总线地址。GMMU 仍然通过 fldPeerIndex 和 HSHUB 路由到正确的 PCIe 端口。
而在 Patch 中,使用了 GMMU_APERTURE_SYS_NONCOH 的逻辑,将 PTE 地址从 fldAddrPeer 换到 fldAddrSysmem,基地址从 Fabric 地址换成 BAR1 物理地址,让 GMMU 将对端显存当作系统内存来访问。
以下以 GPU1 访问 GPU0 显存的场景为例,大体描述一下数据通路:
1.环境准备与 BAR1 空间暴露
主板 BIOS 开启 Above 4G Decoding、Resizable BAR,关闭 PCIe ACS。IOMMU 可配置为 Passthrough 模式或正确配置 P2P DMA 映射支持,保证 PCIe P2P 事务可达;
OS 启动时,为每个 GPU 的 BAR1 空间分配连续的 64 位 PCIe 总线物理地址,地址范围覆盖 GPU 全部显存;
NVIDIA 内核驱动暴露 BAR1 地址映射能力,封装基础的 P2P 接口。
2.地址映射与转换
驱动获取对端 GPU(GPU0)的 BAR1 总线物理基地址,以及显存地址到 BAR1 地址的偏移关系(GPU0 显存内的偏移 = BAR1 总线地址的偏移);
将 GPU0 的 BAR1 总线地址,映射到本地 GPU(GPU1)的可访问地址空间。在 GPU1 的 GMMU 中,该地址被标记为 SYS Aperture,而非 GPU 原生的 VID Aperture;
访问 GPU0 显存内的数据,则需要将 GPU0 的显存偏移转换为对应的 BAR1 总线物理地址(BAR1 基地址 + 显存偏移)。IOMMU 需正确配置以支持 Peer-to-Peer DMA 映射;在 IOMMU 不支持 P2P 映射的场景下,可能需要设置为 Passthrough 模式或禁用,则该地址可直接用于 PCIe 路由。
3.运行时数据访问
GPU1 的 SM 发起对转换后的 BAR1 总线地址的读写请求;
GPU1 的 GMMU 识别到该地址属于 SYS Aperture,将其当作系统物理地址,转发给 PCIe 控制器;
PCIe 控制器发起标准的 PCIe Memory Read/Write TLP 事务,目标地址为 GPU0 的 BAR1 总线地址,通过 PCIe 交换机路由到 GPU0;
GPU0 的 PCIe 控制器收到 TLP 事务,根据 BAR1 的基地址与偏移,转换为本地显存的物理地址,转发给显存控制器完成读写;
数据通过 PCIe Completion TLP 沿原路径返回给 GPU1 的 SM;
整个过程绕过了 CPU 系统内存。
4.3.2.1. BAR1 Mapping 的核心特性与限制
- 不依赖 NVIDIA 原生 Peer 硬件机制,仅需 GPU 支持 ReBAR、PCIe 拓扑支持 P2P 即可实现;
- 完全基于标准 PCIe 协议,仅能通过 PCIe 链路传输,无法利用 NVLink;
- 关键的一点是,地址转换发生在较低层的总线与 DMA 语义层面,对上层应用透明。开发者仍需经由 CUDA Peer Access API 取得合法的 UVA Pointer,而不能直接在用户态 Mmap BAR1 做透明访问。
4.3.3. 代码概览
接下来我们看下 NVIDIA 驱动代码中有关 BAR1 P2P 的具体实现。
4.3.3.1. 能力检测
驱动会首先在 p2p_caps.c::p2pGetCapsStatus() 这里对当前系统环境适配的 P2P 能力,按照 C2C -> NVLink -> PCIe BAR1 -> PCIe Mailbox 的顺序依次检测。
对于 BAR1 P2P 的检测在 p2p_caps.c::_kp2pCapsGetStatusOverPcieBar1():
1.驱动配置检查(是否允许 BAR1 P2P)
if (((pKernelBif->forceP2PType != NV_REG_STR_RM_FORCE_P2P_TYPE_DEFAULT) &&
(pKernelBif->forceP2PType != NV_REG_STR_RM_FORCE_P2P_TYPE_PCIEP2P))
||
((pKernelBif->pcieP2PType != NV_REG_STR_RM_PCIEP2P_TYPE_BAR1) &&
(pKernelBif->pcieP2PType != NV_REG_STR_RM_PCIEP2P_TYPE_AUTO)))
{
return NV_ERR_NOT_SUPPORTED;
}
检查驱动的 P2P 类型配置,BAR1 P2P 需要满足 Regkey 对应的值:
f- orceP2PType 是默认值或 PCIEP2P;
pcieP2PType 是 BAR1 或 AUTO。
2.硬件支持检查(HAL 层)
// from:src/nvidia/generated/g_kern_bus_nvoc.c::__nvoc_init_funcTable_KernelBus_1
// 可以看到,如果不是GH100 | GB100 | GB102 | GB10B | GB110 | GB112 | GB202 | GB203 | GB205 | GB206 | GB207 | GB20B | GB20C,则直接返回失败
static inline NvBool kbusIsPcieBar1P2PMappingSupported_d69453(struct OBJGPU *pGpu0, struct KernelBus *pKernelBus0, struct OBJGPU *pGpu1, struct KernelBus *pKernelBus1) {
return NV_FALSE;
}
/*!
* @brief check if it can support BAR1 P2P between the specified GPUs
* At the point this function is called, the system do not support C2C and
* NVLINK P2P and the BAR1 P2P is the preferred option.
*
* @param[in] pGpu0 (local GPU)
* @param[in] pKernelBus0 (local GPU)
* @param[in] pGpu1 (remote GPU)
* @param[in] pKernelBus1 (remote GPU)
*
* return NV_TRUE if it supports BAR1 P2P between the specified GPUs
*/
NvBool
kbusIsPcieBar1P2PMappingSupported_GH100
(
OBJGPU *pGpu0,
KernelBus *pKernelBus0,
OBJGPU *pGpu1,
KernelBus *pKernelBus1
)
{
NvU32 gpuInst0 = gpuGetInstance(pGpu0);
NvU32 gpuInst1 = gpuGetInstance(pGpu1);
KernelBif *pKernelBif = GPU_GET_KERNEL_BIF(pGpu0);
// Only support if available by default, or if forced by regkey.
if ((pKernelBif->pcieP2PType != NV_REG_STR_RM_PCIEP2P_TYPE_BAR1) &&
!pKernelBus0->getProperty(pKernelBus0, PDB_PROP_KBUS_SUPPORT_BAR1_P2P_BY_DEFAULT))
{
return NV_FALSE;
}
// Not loopback support
if (pGpu0 == pGpu1)
{
return NV_FALSE;
}
// Both of GPUs need to have the static bar1 enabled
if (!kbusIsStaticBar1Enabled(pGpu0, pKernelBus0) ||
!kbusIsStaticBar1Enabled(pGpu1, pKernelBus1))
{
return NV_FALSE;
}
//
// RM only supports one type of PCIE P2P protocol, either BAR1 P2P or mailbox P2P, between
// two GPUs at a time. For more info on this topic, please check bug 3274549 comment 10
//
// Check if there is p2p mailbox connection between the GPUs.
//
if ((pKernelBus0->p2pPcie.peerNumberMask[gpuInst1] != 0) ||
(pKernelBus1->p2pPcie.peerNumberMask[gpuInst0] != 0))
{
return NV_FALSE;
}
return NV_TRUE;
}
这里是 BAR1 P2P 的准入检查,调用 HAL 函数 kbusIsPcieBar1P2PMappingSupported_HAL,检查 2 张 GPU 之间是否满足以下条件:
GPU 架构是否原生支持 BAR1 P2P(Hopper+);
ReBAR 是否启用,BAR1 空间是否完整映射了全部显存。值得一提的是,以下 2 种情况会被直接判断不支持:
vGPU 虚拟化环境下不支持;
Confidential Computing 模式下不支持。
3.覆盖配置检查
if (_kp2pCapsCheckStatusOverridesForPcie(gpuMask, pP2PWriteCapStatus,
pP2PReadCapStatus,
pP2pAtomicsCapStatus))
{
return NV_OK;
}
这里检查 Regkey 是否有写入的强制值。如果有覆盖配置则直接按覆盖值返回,无需进行后续的能力检测。主要包含了以下能力:P2PReadCap、P2PWriteCap、P2PAtomicsCap。
4. 主机系统状态检查
NV_CHECK_OK_OR_RETURN(LEVEL_ERROR,
_p2pCapsGetHostSystemStatusOverPcieBar1(pFirstGpu, &writeCapStatus,
&readCapStatus, bCommonPciSwitchFound));
调用 _p2pCapsGetHostSystemStatusOverPcieBar1 检查主机系统,需至少满足以下任一条件:
有 PCIe Switch;
CPU 为 Ryzen 或是 Xeon SPR。
对比 Mailbox:没有 Intel IOH 的历史包袱检查。
5. PCIe 原子操作能力检查
// If p2p traffic is supported, check the PCIe topology for atomics capability
_p2pCapsGetPcieToplogySupportForBar1Atomics(gpuMask, &atomicsCapStatus);
- 当前直接返回 NOT_SUPPORTED。
4.3.3.2. 建立映射
这里是从 kern_bus_gh100.c::kbusCreateP2PMapping_GH100() 分发到映射建立的入口 kbusCreateP2PMappingForBar1P2P_GH100():
NV_STATUS kbusCreateP2PMappingForBar1P2P_GH100(...)
{
// 虚拟 GPU 不支持
if (IS_VIRTUAL(pGpu0) || IS_VIRTUAL(pGpu1))
return NV_ERR_NOT_SUPPORTED;
// 验证 BAR1 P2P 支持
if (!kbusIsPcieBar1P2PMappingSupported_HAL(pGpu0, pKernelBus0, pGpu1, pKernelBus1))
return NV_ERR_NOT_SUPPORTED;
// 首次映射时创建 IOMMU 映射
if ((pKernelBus0->p2pPcieBar1.busBar1PeerRefcount[gpuInst1] == 0) &&
(pKernelBus1->p2pPcieBar1.busBar1PeerRefcount[gpuInst0] == 0))
{
NV_ASSERT_OK_OR_RETURN(_kbusCreateStaticBar1IOMMUMappingForGpuPair(pGpu0, pKernelBus0,
pGpu1, pKernelBus1));
}
// 增加引用计数
pKernelBus0->p2pPcieBar1.busBar1PeerRefcount[gpuInst1]++;
pKernelBus1->p2pPcieBar1.busBar1PeerRefcount[gpuInst0]++;
return NV_OK;
}
可以看到建立映射前同样先检查了当前的虚拟化环境与 BAR1 P2P 的能力;
busBar1PeerRefcount[] 数组记录每个 GPU 对的 P2P 映射引用次数;
在首次执行 Mapping 时建立 IOMMU 映射。接下来看这里是怎么做的。
1. 获取对端 GPU 的 Static BAR1 DMA 内存描述符
// from kern_bus_gh100.c::_kbusCreateStaticBar1IOMMUMapping()
NvU32 peerGpuGfid;
MEMORY_DESCRIPTOR *pPeerDmaMemDesc = NULL;
NV_ASSERT_OK_OR_RETURN(vgpuGetCallingContextGfid(pPeerGpu, &peerGpuGfid));
// 获取对端 GPU 的 Static BAR1 DMA 内存描述符
pPeerDmaMemDesc = pPeerKernelBus->bar1[peerGpuGfid].staticBar1.pDmaMemDesc;
NV_ASSERT_OR_RETURN(pPeerDmaMemDesc != NULL, NV_ERR_INVALID_STATE);
Static BAR1 结构:每个 GPU 的 BAR1 区域都通过 staticBar1 结构管理;
这里的 pDmaMemDesc 是 DMA 内存描述符,描述了 BAR1 区域的物理地址和大小;
GFID 机制:这里通过 GPU Function ID 区分物理 GPU(GFID=0)和 vGPU 实例。
2. 创建 IOVA 映射(内存描述符层)
// 创建 IOMMU 映射:将对端 GPU 的 BAR1 映射到本 GPU 的 IOVA 空间
NV_ASSERT_OK_OR_RETURN(memdescMapIommu(pPeerDmaMemDesc, pSrcGpu->busInfo.iovaspaceId));
// memdescMapIommu 的核心逻辑
NV_STATUS memdescMapIommu(PMEMORY_DESCRIPTOR pMemDesc, NvU32 iovaspaceId)
{
OBJGPU *pMappingGpu = gpumgrGetGpuFromId(iovaspaceId);
OBJIOVASPACE *pIOVAS = iovaspaceFromId(iovaspaceId);
// 获取或创建 IOVA 映射
status = iovaspaceAcquireMapping(pIOVAS, pMemDesc);
return status;
}
每个 GPU 有独立的 I/O Virtual Address 空间,这里就是将 GPU1 的 BAR1 物理地址映射到 GPU0 的 IOVA 空间中;
这里的 MEMORY_DESCRIPTOR 是内存描述符的抽象,用来统一管理不同类型的内存映射。
3. OS 层创建 Peer DMA 映射
// from os.c::osIovaMap()
else if (peer != nv) // 不同 GPU
{
// 创建 peer DMA 映射
status = nv_dma_map_peer(nv->dma_dev, peer->dma_dev, bIsBar0 ? 0 : 1,
osPageCount, &pIovaMapping->iovaArray[0]);
if (status != NV_OK)
{
NV_PRINTF(LEVEL_INFO,
"%s: failed to map peer (base = 0x%llx, status = 0x%x)\n",
__FUNCTION__, base, status);
return status;
}
pIovaMapping->pOsData = NULL; // 标记为 peer 映射
}
进行 Peer 映射,将对端 GPU 的 BAR 区域映射为本地 GPU 可访问的 DMA 地址;
进行地址转换,将物理地址转换为 GPU 可用的 DMA 地址。
4. 内核 IOMMU API 建立硬件映射
/ from nv-dma.c::nv_dma_map_mmio()
if (nv_dma_use_map_resource(dma_dev))
{
NvU64 mmio_addr = *va;
// 调用内核 DMA 映射 API,建立 IOMMU 页表映射
*va = dma_map_resource(dma_dev->dev, mmio_addr, page_count * PAGE_SIZE,
DMA_BIDIRECTIONAL, 0);
}
// 兼容方案(IOMMU 不可用时,保证在不同硬件配置下都能工作)
else
{
// 直接使用总线地址
NvU64 offset = *va - res->start;
*va = pci_bus_address(peer_pci_dev, bar_index) + offset;
}
其中的 dma_map_resource() 是 Linux 内核 API,用于创建 IOMMU 页表映射;
IOMMU 页表:将对端 GPU 的 BAR1 物理地址映射到本地 GPU 的 IOVA 空间;
这里需要硬件支持,PCIe 控制器和 IOMMU 硬件需要支持 Peer-to-Peer DMA。
4.3.3.3. 数据传输
映射建立完成后,数据传输就由 PCIe 硬件处理,通过标准的 DMA 操作,使用 IOMMU 映射后的对端 GPU BAR1 地址。
NV_STATUS kbusGetBar1P2PDmaInfo_GH100(
OBJGPU *pSrcGpu, // 源GPU
OBJGPU *pPeerGpu, // 对端GPU
KernelBus *pPeerKernelBus,
NvU64 *pDmaAddress, // 输出:对端GPU的DMA地址
NvU64 *pDmaSize // 输出:DMA大小
)
{
NvU32 peerGfid;
MEMORY_DESCRIPTOR *pPeerDmaMemDesc;
// 获取对端 GPU 的 Static BAR1 DMA 内存描述符
NV_ASSERT_OK_OR_RETURN(vgpuGetCallingContextGfid(pPeerGpu, &peerGfid));
pPeerDmaMemDesc = pPeerKernelBus->bar1[peerGfid].staticBar1.pDmaMemDesc;
NV_ASSERT_OR_RETURN(pPeerDmaMemDesc != NULL, NV_ERR_NOT_SUPPORTED);
// 获取对端 GPU BAR1 的 DMA 地址(已通过 IOMMU 映射)
memdescGetPtePhysAddrsForGpu(pPeerDmaMemDesc, pSrcGpu,
AT_GPU, 0, 0, 1, pDmaAddress);
*pDmaSize = memdescGetSize(pPeerDmaMemDesc);
return NV_OK;
}
我们大体看一下读写操作对应的硬件流程:
P2P 写操作(GPU0 -> GPU1)
GPU0 驱动准备 DMA 描述符,目标地址为 GPU1_BAR1_IOVA + offset;
GPU0 的 Copy Engine/DMA 发起 PCIe Posted Write 事务;
事务通过 PCIe 总线到达 GPU1 的 PCIe 接口;
GPU1 硬件识别到这是 BAR1 空间的访问,通过静态 BAR1 映射表,直接转换为 FB 物理地址;
GPU1 将数据写入对应的 FB 物理地址,同时更新 GPU1 的 L2 缓存;
GPU0 的 DMA 引擎确认所有 Posted Write 已被 PCIe Fabric 接收后,通过 Doorbell 或同步点通知上层完成。
P2P 读操作(GPU0 <- GPU1)
GPU0 驱动准备 DMA 描述符,源地址为 GPU1_BAR1_IOVA + offset;
GPU0 的 Copy Engine/DMA 发起 PCIe Non-Posted Read Request 事务;
事务通过 PCIe 总线到达 GPU1 的 PCIe 端口;
GPU1 硬件识别到这是 BAR1 空间的访问,通过静态 BAR1 映射表直接转换为 FB 物理地址;
GPU1 从对应的 FB 物理地址读取数据,这里优先从 L2 缓存读取;
GPU1 构造 PCIe Read Completion TLP,携带读取的数据返回给 GPU0;
GPU0 的 DMA 引擎收到所有 Completion TLP 并重组数据后,触发本地 DMA 完成中断;
数据已写入 GPU0 的本地 FB,可被 GPU0 访问。
4.3.3.4. 清理
调用到 kbusRemoveP2PMappingForBar1P2P_GH100() 会触发释放 P2P 映射,释放资源,清除 BAR1 映射:
N V_STATUS
kbusRemoveP2PMappingForBar1P2P_GH100(...)
{
NvU32 gpuInst0, gpuInst1;
if (IS_VIRTUAL(pGpu0) || IS_VIRTUAL(pGpu1))
{
return NV_ERR_NOT_SUPPORTED;
}
gpuInst0 = gpuGetInstance(pGpu0);
gpuInst1 = gpuGetInstance(pGpu1);
if ((pKernelBus0->p2pPcieBar1.busBar1PeerRefcount[gpuInst1] == 0) ||
(pKernelBus1->p2pPcieBar1.busBar1PeerRefcount[gpuInst0] == 0))
{
return NV_ERR_INVALID_STATE;
}
pKernelBus0->p2pPcieBar1.busBar1PeerRefcount[gpuInst1]--;
pKernelBus1->p2pPcieBar1.busBar1PeerRefcount[gpuInst0]--;
// Only remove the IOMMU mapping between the pair of GPUs when it is the last mapping.
if ((pKernelBus0->p2pPcieBar1.busBar1PeerRefcount[gpuInst1] == 0) &&
(pKernelBus1->p2pPcieBar1.busBar1PeerRefcount[gpuInst0] == 0))
{
_kbusRemoveStaticBar1IOMMUMappingForGpuPair(pGpu0, pKernelBus0, pGpu1, pKernelBus1);
}
NV_PRINTF(LEVEL_INFO, "removed PCIe BAR1 P2P mapping between GPU%u and GPU%u\n",
gpuInst0, gpuInst1);
return NV_OK;
}
4.3.4.5. 流程图
BAR1 P2P 实现的流程如下图所示: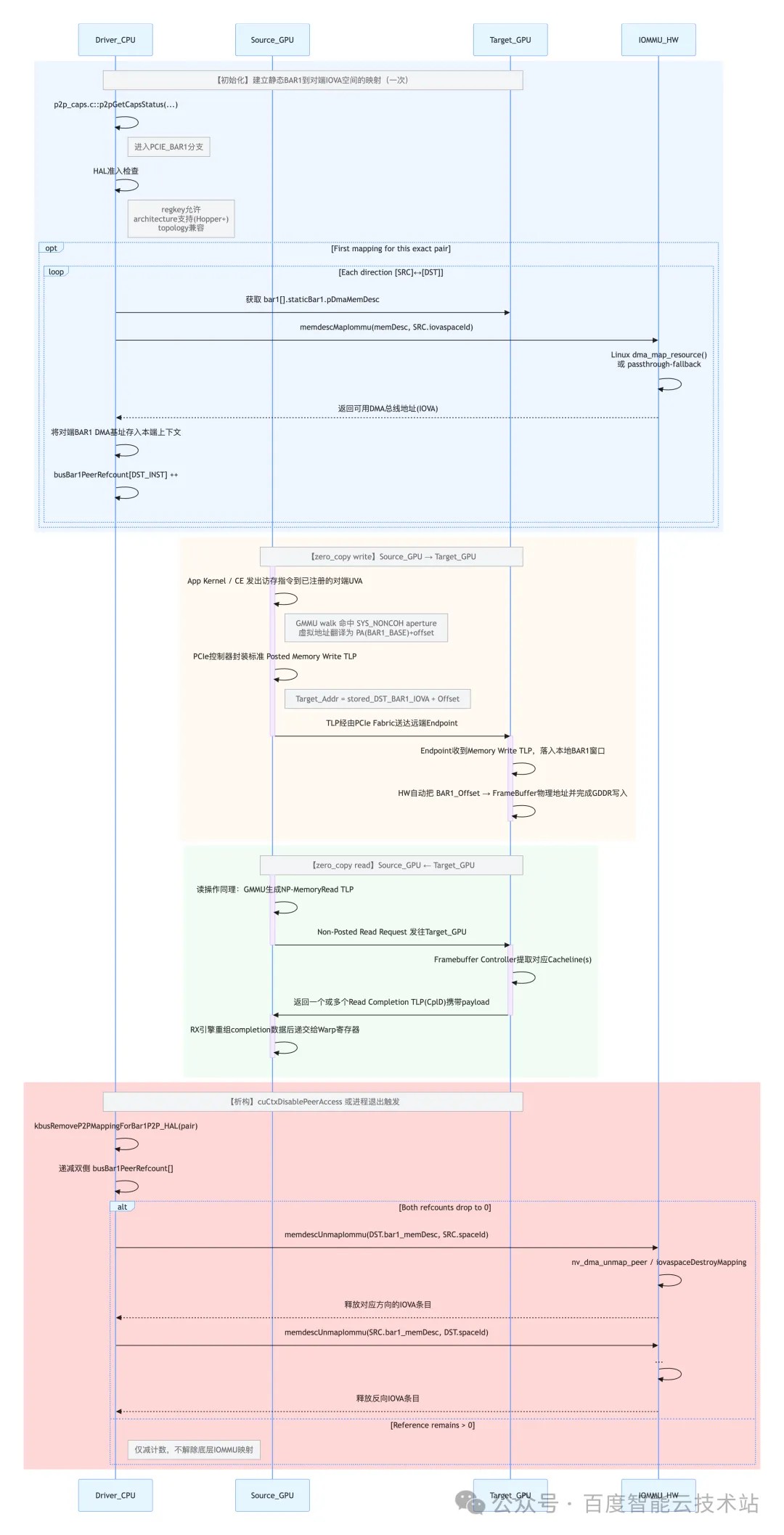
4.4. Mailbox
Mailbox P2P(即驱动枚举类型中的 P2P_CONNECTIVITY_PCIE_PROPRIETARY)是 NVIDIA 为 ReBAR 尚未普及的时代设计的一套私有 Peer-to-Peer 通信机制。该方案自 Fermi 延续至 Ampere,在专业级 Tesla / Quadro 产品线中长期作为默认 PCIe P2P 路径存在。
4.4.1. 原理概述
所谓 Mailbox,是指 GPU 内部集成了一组专用于跨设备握手的 Mailbox Control Registers。真正的业务数据仍走标准 PCIe Transaction Layer Packet(TLP),不会在宽度仅为 32-bit 级别的 Mailbox Regs 上逐片搬运。
其核心思路可概括为:利用 GPU 内部的 Peer ID 空间与 HSHUB 片上互联路由表,把远端显存翻译成本地 GMMU 可直接识别的 PEER Aperture,从而允许 SM 或 Copy Engine 像访问本地 VID Memory 一样发起跨设备读写。 BAR1 在此过程中仅被借用做一小段 MMIO 控制区,用于暴露对方的 P2P 相关寄存器。
4.4.1.1. 依赖的硬件基础
Peer ID & HSHUB Mask:每颗 GPU 维护最多 8 个 Peer Slot(0–7)。当某段 UVA 经 CUDA Runtime 注册为 Remote Allocation 时,GMMU 会将对应的虚拟页标记为 PEER Aperture,并在报文中加入 Peer Index;HSHUB 根据该索引选择下游 PCIe Port;
WMB Tag:单向 32-bit 随机令牌,由 CPU 驱动在初始化阶段分别写入两端,用于过滤非法的设备间访问,防止恶意或误配的访存操作穿透 FrameBuffer;
- BAR1 小窗(仅作控制面):驱动在本地 BAR1 空间中切出一小块区域来映射对端设备的寄存器,使得 A 卡可以直接通过 MMIO 来写 B 卡的 Doorbell/Status 寄存器。注意这块区域与显存本身无关,不直接参与数据迁移;
- 标准 PCIe Link:与 BAR1 P2P 相同,底层仍需 Switch 支持 P2P Routing、ACS/IOMMU 正确放行。
4.4.1.2. 大体工作流程
整个生命周期分为三个阶段:CPU 握手与路由建立 → GPU 数据传输阶段 → CPU 析构阶段。其中真正耗时的数据传输全部发生在第二阶段,无需 Kernel Trap。
1.初始化阶段
- NVIDIA 内核驱动为成对的 GPU 分配专属 Mailbox 硬件资源,建立双向控制通道,配置中断触发条件和状态寄存器,完成 GPU 间的握手认证。这个过程上层 CUDA 应用是透明的。
2.数据传输核心流程
GMMU 地址解析:当 CUDA Kernel 内核对已经注册为 Peer Accessible 的 UVA 执行 Load/Store 时,本地 GPU 的 GMMU 会将该虚拟地址对应的页表项命中为 PEER Aperture。此时 GMMU 会在生成的存储器请求报文头部嵌入预先配置好的 Peer ID,并将其递交给片上的高速互联枢纽 HSHUB;
HSHUB 路由:HSHUB 内部维护着一张以 Peer Index 为索引的路由掩码表。HSHUB 解码该请求的 Peer ID 后,直接将其导向本 GPU 连接至目标方向的 PCIe Root Port / Switch Port,形成一条数据通路。整个过程既不需要陷入 CPU 驱动,也不需要经由 Mailbox 寄存器参与调度;
PCIe Fabric 传输:PCIe 控制器将该请求封装为标准 Memory Read/Write TLP,经 PCIe Switch 或直接 RC 路由抵达对端 GPU 的 PCIe Downstream Port。由于此前已完成静态 BAR1 MMIO 控制区映射和对端 P2P Config/Doorbell 寄存器配置,因此这里的 TLP Payload 就是单纯的业务数据流;
对端 FrameBuffer 完成读写:对端 GPU 收到 TLP 后,其 FrameBuffer Controller 首先校验携带的 WMB Tag,匹配成功后直接将事务转换为本地的 Frame Buffer Physical Address 并完成最终的 DRAM 读写。如果是 Non-Posted Write,则按标准 PCIe Ack 规则回复 Completion;若是 Posted Write,则无需等待回应即可完成流水线提交。
4.4.2. 代码概览
接下来我们结合 NVIDIA 驱动代码,看一下 Mailbox P2P 的具体实现。
4.4.2.1. 初始化
该阶段建立 P2P 连接。
1.Mailbox P2P 资源分配
NV_STATUS kbusCreateP2PMappingForMailbox_GM200(
OBJGPU *pGpu0, OBJGPU *pGpu1,
NvU32 *pPeer0, NvU32 *pPeer1)
{
// 1. 检查硬件是否支持 mailbox P2P
if (!kbusIsMailboxP2PSupported(pGpu0) || !kbusIsMailboxP2PSupported(pGpu1))
return NV_ERR_NOT_SUPPORTED;
// 2. 分配双向 Peer ID
// peer0 = GPU0视角下的GPU1 编号(0-7)
// peer1 = GPU1视角下的GPU0 编号(0-7)
*pPeer0 = kbusAllocPeerId(pGpu0);
*pPeer1 = kbusAllocPeerId(pGpu1);
// 3. 双向配置 HSHUB Peer 掩码,使能片上互联对该 Peer 的路由
kbusConfigureHshubPeerMask(pGpu0, *pPeer0);
kbusConfigureHshubPeerMask(pGpu1, *pPeer1);
// 4. 双向配置 mailbox 通信通道
// 配置 GPU0→GPU1 方向
kbusSetupMailboxes_GM200(pGpu0, pGpu1, *pPeer0, *pPeer1);
// 配置 GPU1→GPU0 方向
kbusSetupMailboxes_GM200(pGpu1, pGpu0, *pPeer1, *pPeer0);
return NV_OK;
}
当用户调用 cuCtxEnablePeerAccess() 时,RM 内核最终会调用到 kbusCreateP2PMappingForMailbox_GM200()
Peer ID 是 GPU 内部用于标识远程 GPU 的唯一编号,范围 0-7,每个 GPU 最多支持 8 个 Peer;
HSHUB 是 GPU 内部的高速 Hub,路由来自 SM、CE 等的 Peer 访存请求;
kbusSetupMailboxes_GM200 调用会建立单方向的通信,需要调用 2 次。
2.单个方向的通道配置
void kbusSetupMailboxes_GM200(
OBJGPU *pLocalGpu, OBJGPU *pRemoteGpu,
NvU32 localPeerId, NvU32 remotePeerId)
{
// 1. 建立 Peer BAR 访问映射
// 将远端GPU的P2P寄存器区域和Mailbox区域映射到本端可访问的总线窗口
kbusSetupPeerBarAccess(pLocalGpu, pRemoteGpu, localPeerId);
// 2. 设置 P2P Domain 访问权限
// 配置本地GPU允许远端GPU访问其P2P Domain
kbusSetupP2PDomainAccess_GM200(pLocalGpu, localPeerId);
// 3. 设置 Mailbox 访问权限
// 配置本地GPU允许远端GPU写入其Mailbox寄存器
kbusSetupMailboxAccess_GM200(pLocalGpu, localPeerId);
// 4. 分配 BAR1 Mailbox 空间
kbusAllocP2PMailboxBar1_GM200(pLocalGpu, localPeerId);
// 5. 写入P2P WMB Tag
// 在远端GPU上写入对应Peer ID的WMB Tag,这用来标识请求来源
kbusWriteP2PWmbTag_GM200(pRemoteGpu, remotePeerId, pLocalGpu->p2pWmbTag);
}
这里配置了本地 GPU 的各种访问权限,其中 kbusSetupPeerBarAccess 是基础,后续的寄存器操作都基于 BAR 映射;
WMB Tag 是一个 32 位的随机数,用于防止恶意或错误的 P2P 请求,只有携带正确 Tag 的请求才会被处理。需要注意的是,WMB Tag 是单向的,每个方向都有自己独立的 Tag。
经过上述初始化操作后,两张 GPU 之间的握手完成,路由已建立。但此时还 没有发生任何应用数据传输。
4.4.2.2. 数据传输
初始化阶段完成后,数据传输就由 GPU 硬件处理,不需要 CPU 参与了。CUDA Runtime 会把 Peer Device 的显存映射到同一套 Unified Virtual Address (UVA) 空间中。此后应用程序看到的就是普通的指针,内核态无需再次陷入。我们大体看一下读写操作对应的硬件流程和触发时机。
P2P 写操作(GPU0 → GPU1)
代码触发时机:CUDA Kernel 中对指向 GPU1 显存的 UVA Pointer 执行赋值语句(如 *dst_remote = src_local_data;);编译器会生成与普通全局内存 Store 相同的指令序列。
大致流程:
GPU0 的 SM 取指译码后将 Store 指令送入 LSU(Load/Store Unit),计算得到完整的 64 位虚拟地址;
GMMU 页表时发现该页属性为 PEER Aperture 并且关联到 GPU1,于是在发出的报文中填入对应的 Peer Index;
HSHUB 检索本地 Peer-to-Port 映射表,将该请求转发给通向 GPU1 的 PCIe 端口;
GPU0 的 PCIe 物理层封装为标准 PCIe Posted Memory Write TLP,Payload 即为待写的数据,目标地址为 UVA 翻译后经系统拓扑决定的目标地址;
GPU1 的 PCIe Endpoint 接收到 TLP,校验 WMB Tag 合法性,若合法则将 TLP 递交至 FrameBuffer Controller,最终转换为针对本地 GDDR 的物理地址;
由于是 Posted Write,无需立即返回 Completion。Store Instruction 在该层级被视为已 Retire,只要满足 CUDA 内存一致性模型即可继续向前推进。
P2P 读操作(GPU0 ← GPU1)
代码触发时机:CUDA Kernel 中对指向 GPU1 显存的 UVA Pointer 执行取值(如 val = *src_remote;);编译器会生成与普通全局内存 Load 类似的指令序列。
硬件大致流程:
GPU0 的 SM 取指译码后将 Load 指令送入 LSU,计算出 64 位虚拟地址;
GMMU 页表命中 PEER Aperture 及对应到 GPU1,于是在发出的报文中填入对应的 Peer Index;
HSHUB 查询 Peer-to-Port 映射表并将请求导向下行 PCIe 端口;
GPU0 的 PCIe Controllers 构造 PCIe Non-Posted Memory Read Request TLP,发送至 Fabric;
GPU1 接收 TLP,验证 WMB Tag,随后从其本地 FrameBuffer 中提取所需的 Cacheline;
GPU1 打包多个 PCIe Read Completion TLP(CplD)沿反向链路送回 GPU0;
GPU0 的 PCIe RX Engine 重组 Completion Data,返回到最初发射该 Load 指令的 Warp/SM,最终将数据填充到目的 General Purpose 寄存器中。
4.4.2.3. 清理
释放资源,关闭 P2P 通道
void kbusDestroyPeerAccess_GM200(OBJGPU *pGpu, NvU32 peerId)
{
// 1. 禁用 P2P Domain 访问
kbusWriteReg32(pGpu, NV_P2P_DOMAIN_CTRL(peerId), 0);
// 2. 禁用 Mailbox 访问
kbusWriteReg32(pGpu, NV_P2P_MAILBOX_CTRL(peerId), 0);
// 3. 清除 Peer BAR 映射
kbusWriteReg32(pGpu, NV_P2P_PEER_BAR_CTRL(peerId), 0);
// 4. 清除 WMB Tag
kbusWriteReg32(pGpu, NV_P2P_WREQMB_L(peerId), 0);
// 5. 释放 Peer ID
kbusFreePeerId(pGpu, peerId);
}
当用户调用 cuCtxDisablePeerAccess() 时就会执行清理工作。
4.4.2.4. 流程图
Mailbox P2P 实现的流程如下图所示: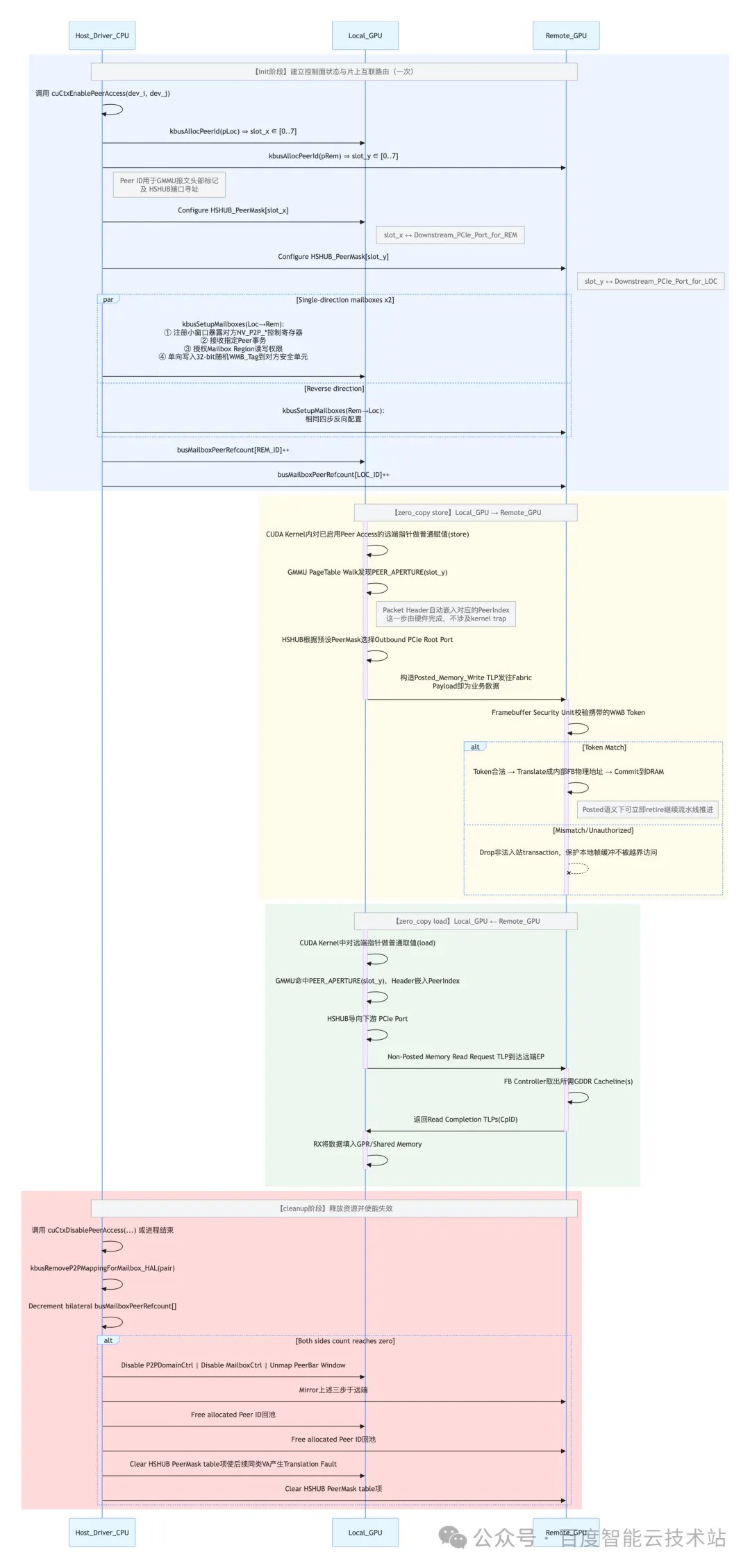
4.5. 性能对比
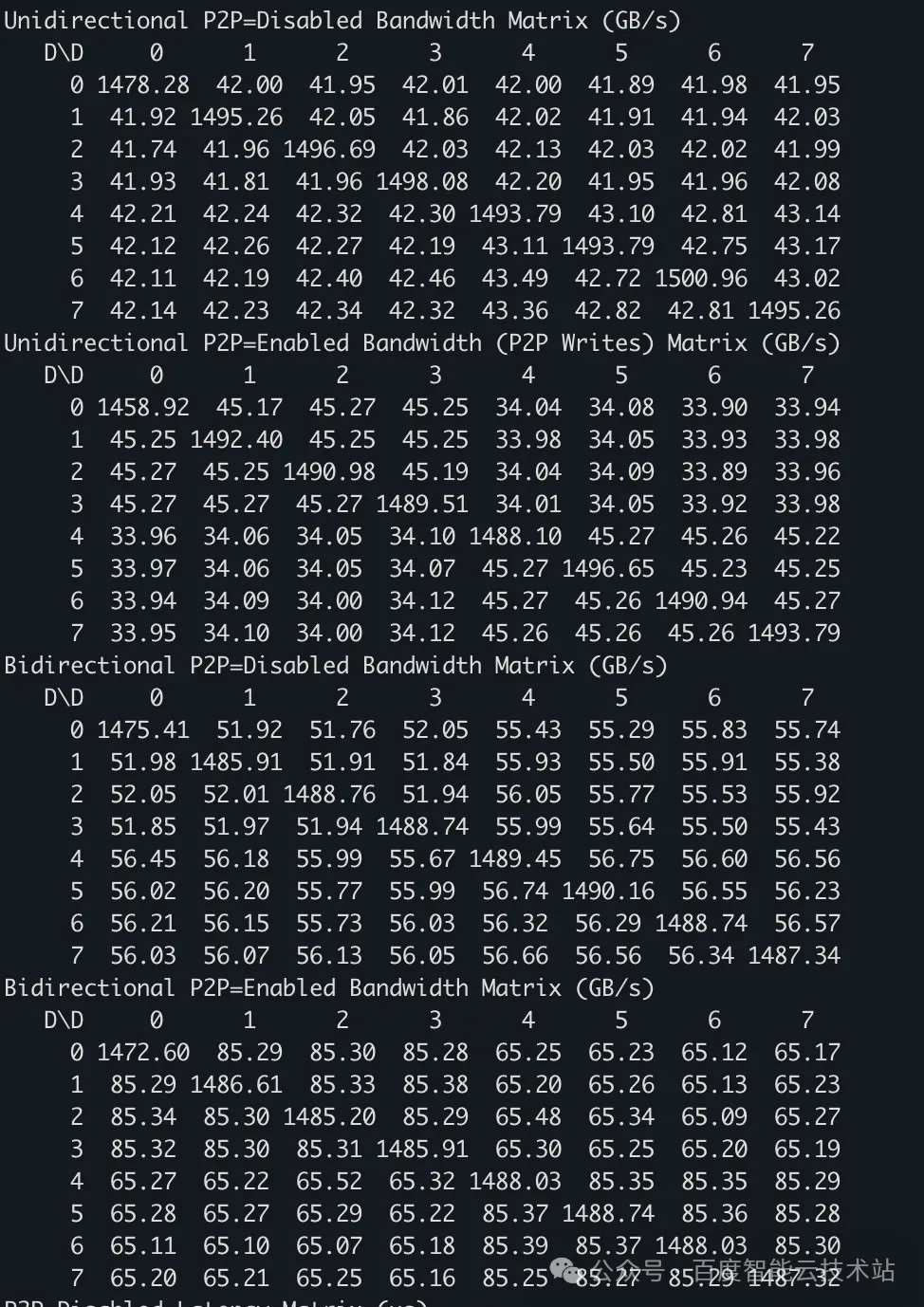
我们以一台支持 PCIe P2P 的 GPU 做 p2pBandwidthLatencyTest 测试,结果如下:
- BAR1 mapping 性能数据
- Mailbox 性能数据
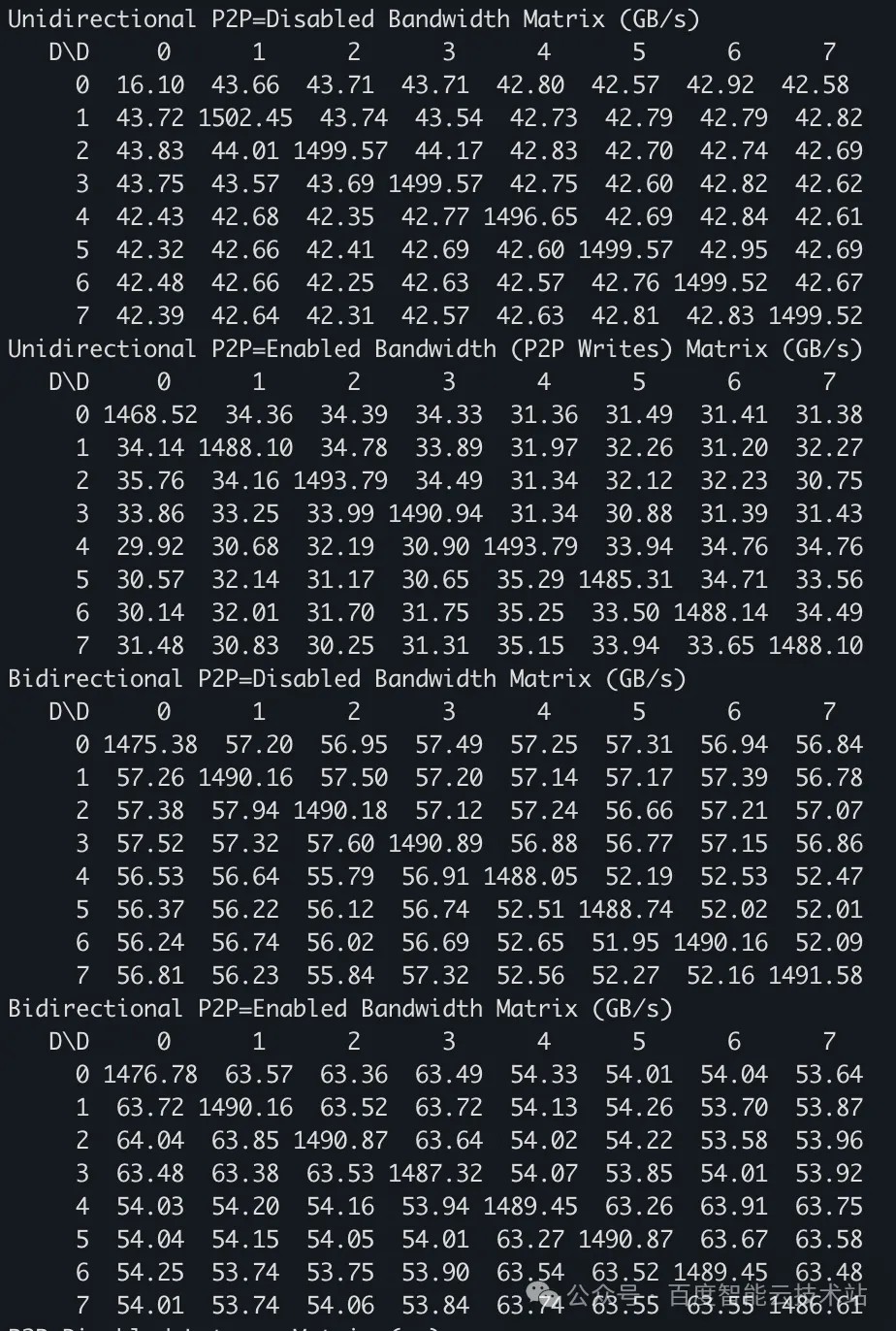
可以看到,BAR1 Mapping 在带宽性能上显著优于 Mailbox P2P(实测约提升 20%~35%),这也是符合预期的。
Mailbox P2P 是小 BAR 时代的妥协性方案,其软硬件设计都围绕「如何用 256MB 的小 BAR 空间,实现对几十 GB 显存的跨 GPU 访问」,不可避免地引入了信令协商、寄存器间接寻址等额外开销,性能上限受限于架构。
而 BAR1 P2P 是 ReBAR 大 BAR 时代的原生架构,彻底消除了小 BAR 的历史包袱。通过静态的全量线性映射,相较于 Mailbox,运行时开销低很多。同时它更符合 PCIe 标准协议,在带宽、延迟、扩展性上实现了对 Mailbox P2P 的性能优势。
5. 结语
GPUDirect P2P 技术路线的走向相对清晰:Mailbox P2P 是当年小 BAR 时代的补丁方案,天生有性能天花板。在 ReBAR 普及后,其应用场景将逐步收窄。
BAR1 P2P 才是更合理的方案。靠着大 BAR 一次性映射完所有显存,跑起来低额外开销,能把 PCIe 总线的带宽几乎榨干,应该成为 PCIe P2P 主推的通用方案。以后跨设备、跨厂商的互联应该会越来越容易。
至于 NVLink,那是给超算、千亿大模型训练准备的顶级配置。BAR1 P2P 更多覆盖从消费卡到入门专业卡的绝大多数 PCIe-only 的互联场景,两者互不冲突。
这次社区支持部分 GPU 的 GPUDirect P2P 能力是一次很好的实践,最大程度地挖掘了 GPU 设备的能力,实现了技术普惠大众。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册